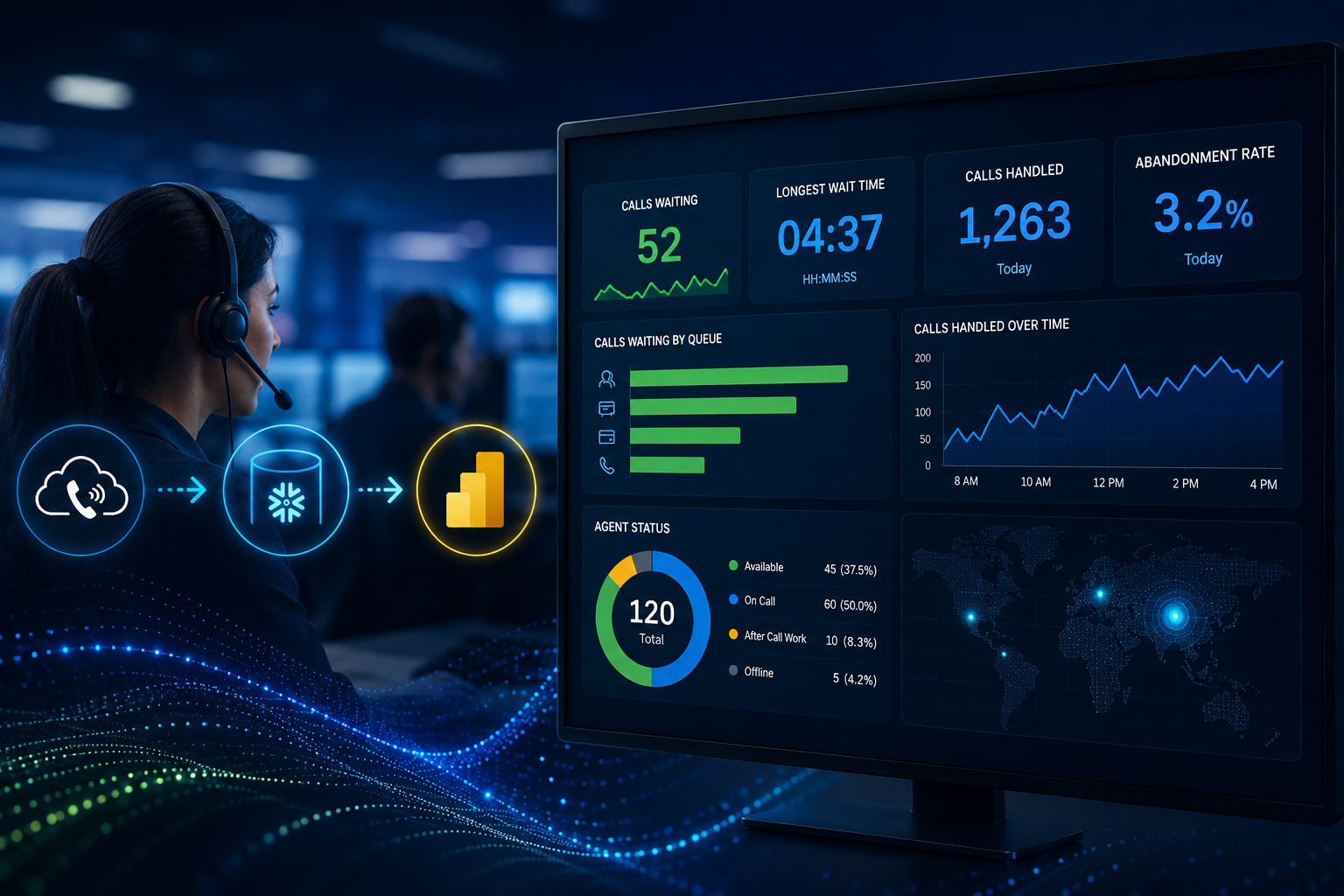

What happens when you connect Power BI to Amazon Connect event data via DirectQuery and why the hardest problems had nothing to do with DirectQuery.
𝗜𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻
“We need a dashboard that tells us exactly how many calls are waiting right now.”
It is one of the most common requests in contact center analytics. On paper, the architecture looks clean: Amazon Connect streams events into Snowflake, Power BI connects via DirectQuery, and supervisors get a live operational view. No refresh schedule. No stale data. Real time.
What follows is what happens when you build that solution in production and why the hardest problems had nothing to do with DirectQuery.
𝗪𝗵𝘆 𝗗𝗶𝗿𝗲𝗰𝘁𝗤𝘂𝗲𝗿𝘆 𝗦𝗲𝗲𝗺𝗲𝗱 𝗟𝗶𝗸𝗲 𝘁𝗵𝗲 𝗢𝗯𝘃𝗶𝗼𝘂𝘀 𝗔𝗻𝘀𝘄𝗲𝗿
Operational contact center dashboards have a different freshness requirement than most BI reporting. A metric like “Calls Waiting” has a useful lifespan measured in seconds, not hours. A scheduled Import refresh is operationally useless for a floor supervisor deciding whether to pull an agent off a break.
DirectQuery addresses this directly. Every page load issues a fresh SQL query to the source and returns the current state of the data. No copy, no lag, and no refresh schedule. For a contact center monitoring use case, it appears to be exactly the right tool.
That assumption held until we ran the first version against real Amazon Connect data.
𝗧𝗵𝗲 𝗥𝗲𝗮𝗹 𝗣𝗿𝗼𝗯𝗹𝗲𝗺 𝗪𝗮𝘀 𝗡𝗼𝘁 𝗗𝗶𝗿𝗲𝗰𝘁𝗤𝘂𝗲𝗿𝘆
Amazon Connect does not write one row per call. It writes one row per state change. A single caller generates at least five distinct records as the call moves through its lifecycle; initiated, queued, connected to the IVR, connected to an agent, and disconnected. Every one of those rows shares the same contact identifier.
Without deduplication, a COUNT of records does not count calls. It counts events. A dashboard showing 500 waiting callers when there are 50 is not a DirectQuery problem. It is a data modeling problem that DirectQuery makes impossible to hide.
Three issues compounded this quickly:
- 𝗪𝗮𝗶𝘁𝗶𝗻𝗴 𝗰𝗮𝗹𝗹 𝗱𝗲𝘁𝗲𝗰𝘁𝗶𝗼𝗻. The instinct is to flag a call as waiting when its connected and disconnect timestamps are both NULL. This works until you account for pipeline latency — disconnect events sometimes arrive several seconds after the call has ended. During that window, a completed call appears active. The correct approach is to use the authoritative QUEUED event type as the signal rather than inferring state from absent timestamps.
- 𝗪𝗮𝗶𝘁 𝘁𝗶𝗺𝗲 𝗰𝗮𝗹𝗰𝘂𝗹𝗮𝘁𝗶𝗼𝗻. Elapsed wait time is measured from when a call entered the queue to when it connected to an agent. Both timestamps are stored as UTC strings, but contact centers operate in local time. Without explicit timezone conversion applied before Power BI sees the data, every time-based metric is wrong by several hours.
- 𝗤𝘂𝗲𝘂𝗲 𝗰𝗹𝗮𝘀𝘀𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻. Normalizing numbers to a consistent format before classification is not optional and matching on raw string values is fragile.
1. 𝗕𝘂𝗶𝗹𝗱 𝘁𝗵𝗲 𝗥𝗲𝗽𝗼𝗿𝘁𝗶𝗻𝗴 𝗟𝗮𝘆𝗲𝗿 𝗙𝗶𝗿𝘀𝘁
The most impactful decision we made was to stop querying raw event tables from Power BI and start querying curated Snowflake views instead.
Those views handled everything the dashboard layer should never touch: contact-level deduplication using window functions, timezone conversion applied once at the source, queue classification, and waiting call detection based on event type rather than timestamp inference.
For call metrics, a single pre-aggregated view returned one summary row containing every KPI — per-queue waiting counts, handled call totals, and the longest wait time formatted as HH:MM:SS. Power BI received a prepared result and displayed it. For agent status, a deduplicated view returned one row per agent representing their most recent status event.
Dashboard load time dropped from over four seconds to under one. The SQL Power BI sent to Snowflake became simpler and more predictable. Business logic was documented in SQL where any engineer could read and validate it, rather than buried in DAX measures referencing raw tables.
2. 𝗗𝗶𝗿𝗲𝗰𝘁𝗤𝘂𝗲𝗿𝘆 𝗘𝘅𝗽𝗼𝘀𝗲𝘀 𝗪𝗵𝗮𝘁 𝗜𝗺𝗽𝗼𝗿𝘁 𝗠𝗼𝗱𝗲 𝗛𝗶𝗱𝗲𝘀
Import mode loads data into VertiPaq’s in-memory engine, which compensates for a surprising amount of data model inefficiency. Poorly structured joins, excessive cardinality, and missing aggregations can go unnoticed because VertiPaq absorbs the cost at refresh time.
DirectQuery has no such compensation. Every visual generates SQL that runs against the source database as written. A poorly designed data model does not just affect refresh speed — it affects every user on every interaction at runtime.
The difference between querying a flat event table and a clean star schema on Snowflake was consistent and measurable. Clean schema queries executed in under 300 milliseconds. Flat table queries on the same data took multiple seconds.
3. 𝗣𝘂𝘀𝗵 𝗖𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻 𝘁𝗼 𝘁𝗵𝗲 𝗦𝗼𝘂𝗿𝗰𝗲
In Import mode, DAX is the calculation engine. Measures run against VertiPaq and return results quickly regardless of complexity. In DirectQuery, every DAX measure must translate into SQL that executes at the source. When that translation is clean, performance is good. When it generates inefficient SQL, the cost appears on every user interaction.
Three specific DAX patterns created problems:
- 𝗧𝗶𝗺𝗲 𝗶𝗻𝘁𝗲𝗹𝗹𝗶𝗴𝗲𝗻𝗰𝗲 𝗳𝘂𝗻𝗰𝘁𝗶𝗼𝗻𝘀. Functions like TOTALYTD() could not always be translated into a single Snowflake aggregation, forcing a fallback to daily-granularity data processed locally by the Formula Engine. We replaced them with pre-calculated Boolean date flags in the source view.
- 𝗗𝗜𝗩𝗜𝗗𝗘() 𝘃𝘀 𝗜𝗙(). DIVIDE() generated less efficient SQL against Snowflake than IF(B = 0, BLANK(), A / B), which translates directly to a native CASE WHEN statement. Standard Power BI guidance does not always transfer to DirectQuery environments.
- 𝗖𝗮𝗹𝗰𝘂𝗹𝗮𝘁𝗲𝗱 𝗰𝗼𝗹𝘂𝗺𝗻𝘀. These computed row-by-row at query time in DirectQuery rather than once at refresh. We eliminated them from DirectQuery tables entirely and moved the equivalent logic to the source views.
4. 𝗥𝗲𝗽𝗼𝗿𝘁 𝗗𝗲𝘀𝗶𝗴𝗻 𝗔𝗳𝗳𝗲𝗰𝘁𝘀 𝗤𝘂𝗲𝗿𝘆 𝗩𝗼𝗹𝘂𝗺𝗲
A page with twelve visuals fires twelve SQL queries to Snowflake on every load. With cross-filtering enabled and multiple users on the dashboard simultaneously, the query volume becomes significant, and it directly affects both performance and compute cost.
Two changes made a meaningful difference:
- 𝗤𝘂𝗲𝗿𝘆 𝗥𝗲𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝘀𝗹𝗶𝗰𝗲𝗿 𝗨𝗫. Enabling Query Reduction and adding Apply buttons to slicers stopped the dashboard from firing a new database query on every individual filter selection. Users interact with slicers and commit the change in one clean action.
- 𝗧𝗵𝗲 𝘀𝗶𝗻𝗴𝗹𝗲-𝗿𝗼𝘄 𝗮𝗽𝗽𝗿𝗼𝗮𝗰𝗵. The pre-aggregated view reduced six separate card visuals each previously triggering an individual Snowflake query to a single query returning one row with six columns. Power BI bound each card to a specific column. Six queries became one.
5. 𝗧𝗵𝗲 𝗛𝗶𝗱𝗱𝗲𝗻 𝗖𝗼𝘀𝘁 𝗼𝗳 𝗦𝗻𝗼𝘄𝗳𝗹𝗮𝗸𝗲 𝗖𝗼𝗺𝗽𝘂𝘁𝗲
Data freshness is not just a performance trade-off, it is a financial one. When you have dozens of supervisors keeping dashboards open all day with page auto-refresh running, you are running an open tap on Snowflake credit consumption.
By default, warehouses auto-suspend after a few minutes of inactivity. A steady stream of automated dashboard queries destroys this safety net, preventing the virtual warehouse from ever spinning down.
𝗪𝗮𝗿𝗲𝗵𝗼𝘂𝘀𝗲 𝗰𝗼𝗻𝘁𝗮𝗶𝗻𝗺𝗲𝗻𝘁 𝘀𝘁𝗿𝗮𝘁𝗲𝗴𝘆 𝘄𝗲 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁𝗲𝗱
-
𝗗𝗲𝗱𝗶𝗰𝗮𝘁𝗲𝗱 𝘄𝗮𝗿𝗲𝗵𝗼𝘂𝘀𝗲 𝗮𝗹𝗹𝗼𝗰𝗮𝘁𝗶𝗼𝗻. Power BI DirectQuery traffic was isolated onto its own tightly sized Snowflake virtual warehouse, ensuring dashboard query spikes never affected core data engineering workloads.
-
𝗔𝗴𝗴𝗿𝗲𝘀𝘀𝗶𝘃𝗲 𝗮𝘂𝘁𝗼-𝘀𝘂𝘀𝗽𝗲𝗻𝗱. Because query volume was high but transactional, we reduced the warehouse auto-suspend timeout to 60 seconds.
-
𝗠𝘂𝗹𝘁𝗶-𝗰𝗹𝘂𝘀𝘁𝗲𝗿 𝗰𝗼𝗻𝗰𝘂𝗿𝗿𝗲𝗻𝗰𝘆 𝘀𝗰𝗮𝗹𝗶𝗻𝗴. Instead of sizing up to a larger warehouse tier, we enabled Multi-Cluster Warehouses in Economy Mode. Snowflake scales out horizontally during supervisor peak hours and spins down clusters the moment traffic subsides.
𝗗𝗶𝗿𝗲𝗰𝘁𝗤𝘂𝗲𝗿𝘆 𝗖𝗵𝗲𝗰𝗸𝗹𝗶𝘀𝘁 𝗳𝗼𝗿 𝗥𝗲𝗮𝗹-𝗧𝗶𝗺𝗲 𝗗𝗮𝘀𝗵𝗯𝗼𝗮𝗿𝗱𝘀
Apply these before any DirectQuery model goes to production:
- Curated views handle deduplication, timezone conversion, and business logic; raw event tables are never queried directly
- All aggregations that can be computed at the source are computed at the source
- Query folding is intact on every Power Query transformation step
- Star schema enforced — facts and dimensions separated; bidirectional relationships eliminated
- Assume Referential Integrity enabled on clean join paths
- Source tables clustered on the columns Power BI filters most frequently
- Query Reduction enabled with Apply buttons on slicers
- Dedicated Snowflake warehouse configured with aggressive auto-suspend and concurrency scaling
- Performance Analyzer run on every visual — slow queries investigated at the source, not in DAX
- Calculated columns eliminated from DirectQuery tables
- Time intelligence DAX replaced with pre-calculated source flags
- Self-service DAX creation restricted on live DirectQuery models
- A validation query exists for every single KPI
- Page auto-refresh explicitly configured and load-tested in the Power BI Service
𝗙𝗶𝗻𝗮𝗹 𝗧𝗵𝗼𝘂𝗴𝗵𝘁𝘀
Supervisors now have a live view of queue depth, agent availability, and wait times. The dashboard loads in under a second. The numbers match direct database queries. Every metric is documented and independently verifiable.
But if we had to name one decision that determined whether the project succeeded, it was building clean Snowflake views before connecting Power BI to anything.
DirectQuery did not make the dashboard fast. The data model made it fast. DirectQuery simply allowed Power BI to read from a well-designed source in real time.
The mistake most teams make is treating DirectQuery as the solution to a real-time reporting requirement. It is not. It is the connection layer on top of a solution that must be built correctly. If the data model is poor, DirectQuery surfaces that. If business logic lives in DAX instead of SQL, DirectQuery penalizes it. If the source is not optimized for the queries Power BI will generate, DirectQuery exposes it on every page load.
Everything that made this work happened in Snowflake. By the time data reached Power BI, the hard work was already done.
|
𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗮 𝗿𝗲𝗮𝗹-𝘁𝗶𝗺𝗲 𝗰𝗼𝗻𝘁𝗮𝗰𝘁 𝗰𝗲𝗻𝘁𝗲𝗿 𝗱𝗮𝘀𝗵𝗯𝗼𝗮𝗿𝗱? 𝗪𝗲’𝗿𝗲 𝘀𝘁𝗿𝗮𝗶𝗴𝗵𝘁𝗳𝗼𝗿𝘄𝗮𝗿𝗱 𝘁𝗼 𝘁𝗮𝗹𝗸 𝘁𝗼. Armely delivers Power BI, Snowflake, and Microsoft Fabric solutions built to be accurate, fast, and maintainable.
|