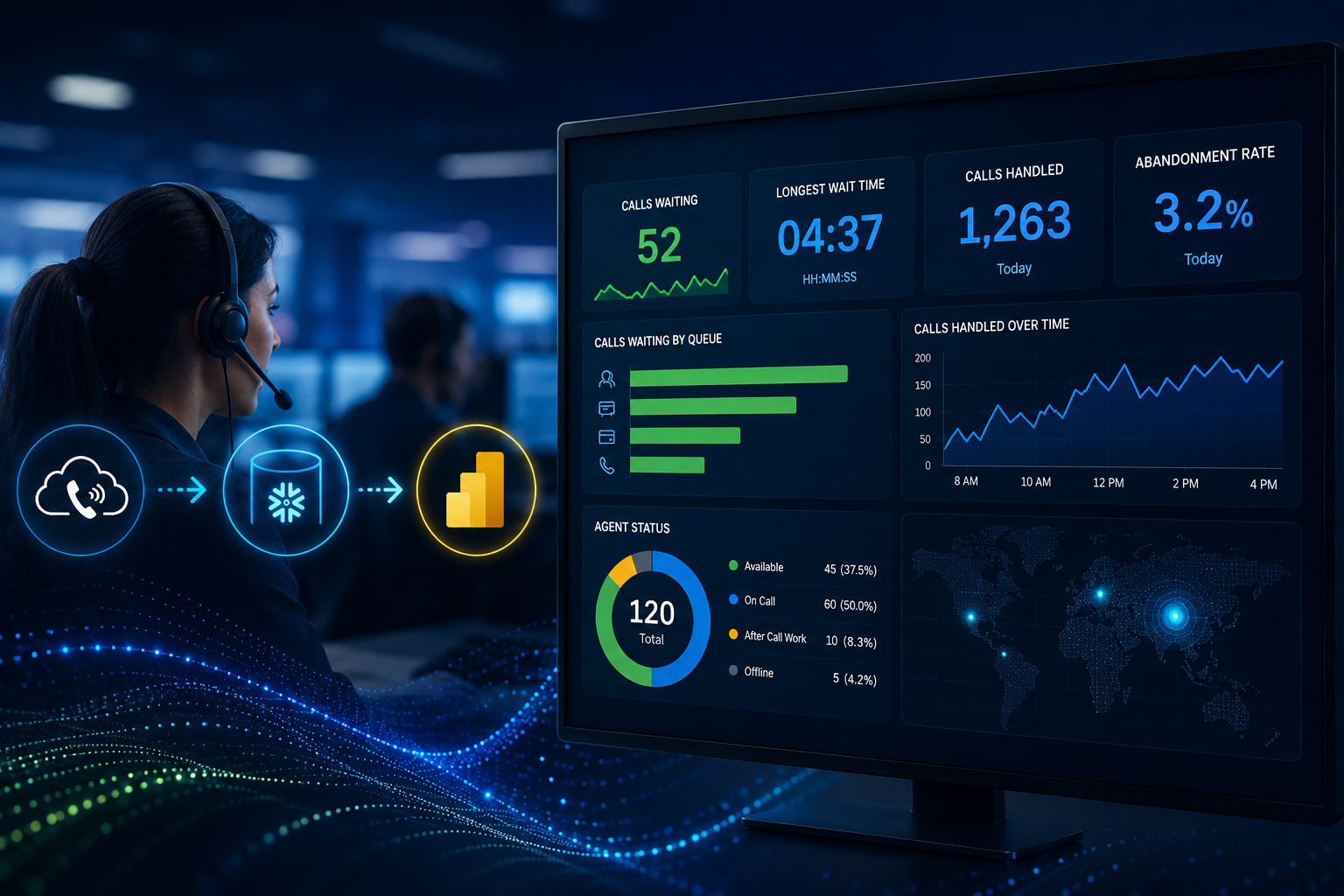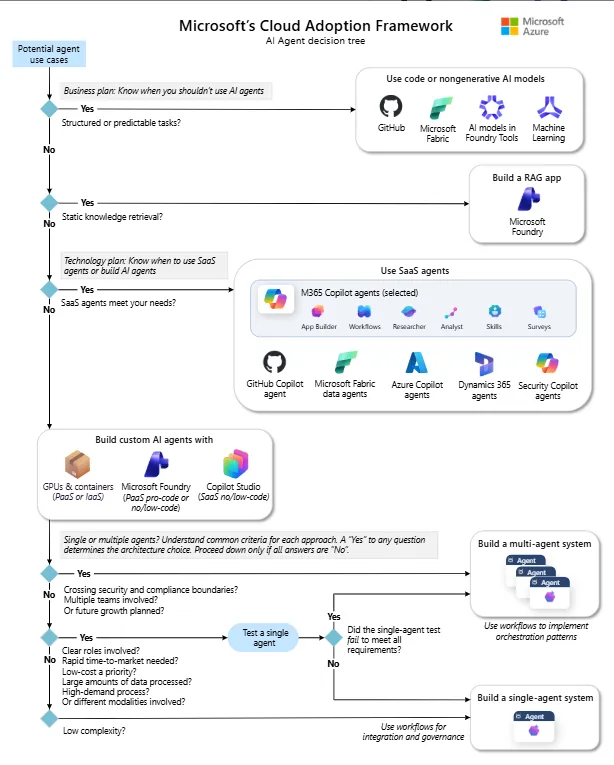

Let’s be honest. There was a time, not so long ago, when every AI feature we shipped came with a quiet anxiety attached to it. Not about whether the feature would work. About the invoice at the end of the month.
Token counts, API rate limits, latency spikes when the internet decided to have a moment. These were the invisible taxes on every smart thing we tried to build. Working on internal AI platforms, every call to a frontier model felt like watching money drain in real time. The product was great. The bill was a conversation.
Then, somewhere between a GitHub notification and a quiet Thursday afternoon, we came across something Microsoft had been quietly building: Foundry Local. It felt like someone had finally acknowledged a problem we had been living with.
Here is the full story, including what has changed since it launched, what developers are actually doing with it, and one thing that happened this week that makes the whole argument land harder than ever.
What Is Foundry Local, For Those Just Joining
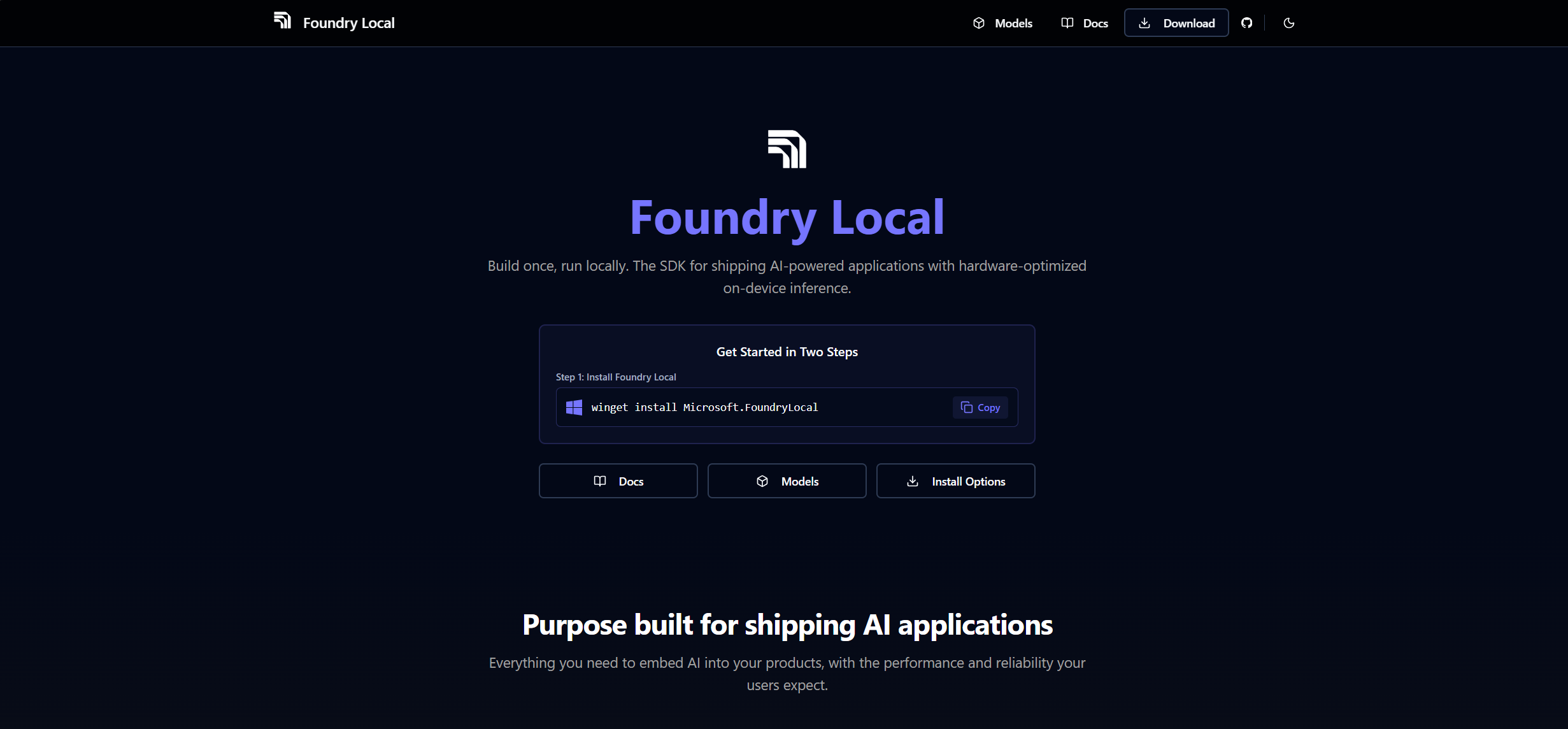
At its core, Foundry Local is Microsoft’s SDK for running AI models entirely on your own device. No cloud. No Azure subscription required. No per-token cost. All inference happens on-device — your prompts never leave your machine, responses start immediately with zero network latency, and your app works even when the internet does not.

On-device inference: the same models running across Intel, AMD, Qualcomm, and NVIDIA silicon — no cloud required.
What makes it different from older local inference tools is the problem it actually solves: cross-platform AI portability for developers shipping real applications to real users. Before Foundry Local, building an AI app that ran locally across different hardware meant writing your own device-detection logic, packaging separate builds for different execution providers, and debugging bizarre cross-platform issues at 11pm. Foundry Local handles all of that automatically.
It detects NPU first, then GPU, then falls back to CPU. It works across NVIDIA, Intel, Qualcomm, and AMD silicon. Chat and audio via Whisper are bundled in a single runtime. And it is built on ONNX Runtime, which keeps the footprint small and performance solid.
The install on Windows is straightforward:
winget install Microsoft.FoundryLocal
Run your first model:
foundry run phi-4
First run downloads the model. Every run after that, it is just there, cached and ready. No API key. No account. No waiting room.
What Has Changed Since Launch
Microsoft has been shipping at a serious pace. Here is what matters.
Foundry Local can now run large multimodal models covering text, image, and audio on local NVIDIA GPU hardware with zero cloud connectivity required. The APIs mirror the cloud surface exactly: Responses API, function calling, agent services — same code, different runtime. Organisations in government, defence, finance, healthcare, and telecom can now run serious AI workloads completely disconnected. Not a trimmed-down local version. The actual thing.
The core REST surface is now production-ready with GA SLAs. SDKs across Python, .NET, JavaScript/TypeScript, and Java all shipped new betas targeting these endpoints. The tooling has matured from an interesting experiment into something you can genuinely build a business on.
Phi-4 Vision is now available locally for image understanding without a cloud call. Claude Opus 4.6 and Sonnet 4.6 arrived in Microsoft Foundry with 1 million token context in beta. DeepSeek V3.2 landed with 128K context and faster reasoning. GPT-5.4 went GA in March. For local use, Phi-4-mini-reasoning handles a surprising workload at 3.15 GB on GPU. Qwen 2.5 Coder remains one of the most practical small models for developer tools at under 1 GB.
Multi-agent workflows, persistent memory, durable orchestration, and a managed runtime where agents can pause for human approval and survive process restarts. The pattern is powerful: your agent does the heavy lifting, pauses, waits for approval, then picks up exactly where it left off. For document review, infrastructure changes, or any approval-based workflow, this is a real step forward.
A Tool Catalog for discovering and configuring agent tools, an Agent Inspector with F5 debugging, and a redesigned Agent Builder. You can now power GitHub Copilot chat with your local Foundry models, keeping queries private and eliminating cloud costs for the bulk of daily coding assistance.
What People Are Actually Doing With It
The pattern we keep seeing across projects is consistent: local models handle the volume, cloud models handle the complexity.
Healthcare teams are using Foundry Local to process patient intake forms and clinical notes locally, never sending sensitive data to a cloud API. Legal teams are running first-pass document review locally before escalating complex matters to a frontier model. Engineering teams are using Qwen 2.5 Coder as a free background code reviewer before pushing to production.
On Mela AI, Armely’s internal AI platform, the hybrid routing has held up well. Simple queries, document summarization, quick lookups, and voice-to-text go local. Complex reasoning, long-context analysis, and anything needing the freshest model capabilities go to Azure. The switch between them is invisible to users. The cost difference is very visible on the invoice — and it is a pleasant number.
Now, About This Claude Code Situation
Something happened on April 21, 2026 that is directly relevant to everything we have been discussing, so let’s address it plainly.
Anthropic quietly removed Claude Code from the $20 Pro plan. No announcement. No notice period. Developers noticed the pricing page had been updated, the documentation had been updated, and there was a red X where a checkmark used to be. Claude Code now requires the Max plan at $100 per month minimum.
The response online was immediate and not kind. Anthropic’s head of growth described it as a small test on roughly 2% of new prosumer signups and said existing subscribers were not affected. Except the official documentation had already been changed, which made the framing difficult to take seriously. They eventually reverted the public pricing page. But the trust damage was already real.
You are not buying capability. You are renting access, and the terms can change while you are mid-project.
We understand the business logic. Claude Code, especially after Opus 4, became a genuinely heavy workload. Long-running agentic coding sessions consume an enormous number of tokens. Someone paying $20 a month and running multi-hour coding agents is consuming far more compute than a $20 subscription was ever priced to cover. Anthropic had to respond to the economics somehow.
But the way it was done revealed something important. The developers who are most upset right now are not being irrational. They built workflows, habits, and client deliverables around a tool that cost $20 per month. That tool now costs $100 per month at minimum. A 400% increase with no notice. For an indie developer or a small team operating on tight margins — especially outside of high-salary markets — that is not a minor inconvenience. It is a fundamental change to what the product costs.
This is the strongest argument for local AI we have seen in a while. Not because local models can fully replace Claude Code at the same quality level. They cannot — not yet. But because every time a proprietary provider moves the goalposts, the case for owning your own inference layer gets stronger. Foundry Local with a Qwen 2.5 Coder model handles a meaningful slice of what Claude Code handles. Enough to keep your workflows running while you figure out what to do about the subscription.
The developers who will be fine are the ones who never put all their capability in one rented basket.
A Practical Solution: The Hybrid Architecture
Here is what is actually working across real projects.
Tier 1 — local, free, always available: Routine code review, summarization, syntax fixes, documentation generation, quick codebase questions. Run Qwen 2.5 Coder or Phi-4 via Foundry Local. Zero cost per query. Works offline. No subscription risk.
Tier 2 — cloud, used deliberately: Complex multi-file refactors, architecture decisions, debugging deeply tangled logic, anything that genuinely needs frontier capability. Use the cloud tier or API for sessions that truly require it.
The routing logic is simpler than people expect. A heuristic based on query length, task complexity, and file scope gets you 80% of the way there. The remaining 20% you route based on judgment about the task at hand.
const getInferenceClient = async (taskComplexity) => {
const isOnline = await checkConnectivity();
if (!isOnline || taskComplexity === 'simple') {
return {
baseURL: 'http://localhost:5272/v1',
model: 'qwen2.5-coder-0.5b',
apiKey: 'local'
};
}
return {
baseURL: process.env.AZURE_ENDPOINT,
model: 'claude-sonnet-4-6',
apiKey: process.env.AZURE_API_KEY
};
};
Both return the same OpenAI-compatible response structure. Your application code does not change. Only the endpoint and model name do.
What Businesses Need to Do Right Now
Stop treating AI subscriptions as infrastructure. Subscriptions are convenient. They are not reliable infrastructure. The Claude Pro situation this week is not an isolated event. It is part of a broader pattern: companies launch powerful features at accessible prices to build adoption, then gate those features behind premium tiers once usage is established. OpenAI has done it. Google has done it. Anthropic just did it. Plan accordingly.
Build a local fallback into everything you ship. This does not mean routing everything through local models. It means having a local layer that keeps your application functional and your core workflows running when cloud tiers change, get expensive, or go down. Foundry Local makes this straightforward to implement. There is no good reason not to have it.
Know your token economics before committing to a tier. Claude Code sessions can burn through thousands of tokens per task. If developers are running it heavily, the $20 plan was never going to hold. Run the actual numbers: sessions per day, average context size, model calls per task. Then pick the tier that fits — or use the API with a hard usage cap so you control the ceiling.
For enterprise teams, the February 2026 sovereign cloud announcements are worth a serious evaluation. Large multimodal models running fully disconnected on your own hardware, with APIs that mirror the cloud surface exactly, is a real option now. If any of your clients have data sovereignty requirements, this conversation should already be on the table.
The Bigger Picture Has Clarified, Not Changed
The proprietary frontier models are not going anywhere. They set the quality ceiling and you will want access to them for work that genuinely requires it. But the pricing changes, rate limit adjustments, model deprecations, and access tier shuffles are going to keep happening. The developers who are building sustainably are the ones who treat cloud AI as a premium resource used deliberately — not a utility left running in the background.
Foundry Local gives you that option. A free, fast, private, always-available intelligence layer running on hardware you already own. A capable starting point for the majority of queries, with the cloud waiting for when you genuinely need it.
When Anthropic’s pricing page updated quietly this week, the teams running hybrid architectures had a calm morning. Everyone else was scrambling.
Own your local inference layer. Build the hybrid. Stop renting what you can own.